안녕하세요 오늘은 ECCV 2018에 나온 Stereo network를 이용해서 Monocular depth estimation 성능 개선을 하는 논문에 대해서 리뷰를 하려고 합니다.
아이디어는 정말 간단합니다.
3단계 Step으로 이루어 진다고 생각하면 되는데요,
1. Stereo network를 synthetic data를 이용해서 훈련 시킨다.
2. 위에서 훈련 시킨 Stereo network를 real data를 이용해서 supervised 방식으로 finetuning을 하거나, unsupervised 방식으로 finetuning을 한다.
3. 위에서 완료된 stereo network를 이용해서 예측 치를 뽑고, 그것을 monocular network에서 나온 예측치와 비교해서 mono depth를 예측하고 성능을 향상 시킨다.
이것이 해당 논문의 내용 전부라고 보시면 될 것 같습니다.

먼저 위의 그림은 해당 논문의 전체적인 Architecture이다.
Training Proxy Stereo Matching Network with Synthetic Data
기존 depth estimation에서는 많은 양의 real dataset이 필요로 하는데, real dataset을 얻기는 굉장히 힘듭니다. 또한, real data에 대해서 그에 대응하는 ground truth 정답을 만들기도 굉장히 힘이 듭니다. 따라서 해당 논문에서는 적은 양의 real data 문제를 해결하기 위해서 처음 단계에서 synthetic data 즉 합성된 data를 이용해서 훈련을 진행한다.
일단 기본적으로 stereo에서 사용하는 L1 loss, 즉, 정답과 예측치의 차이는 있다고 보면 된다.

그리고, 여기서는 occlusion 영역을 검출하는데, 해당 논문에서는 정석대로 정답 left disparity와 정답 right disparity를 정답 left disparity를 이용해서 warping 시킨 것의 차가 1 이하인 pixel을 occusion이라고 하였다. Occusion 영역은 0, occlusion이 아닌 영역은 1로 표시가 된다. M*ij는 정답 occlusion map이라고 생각하면 된다.
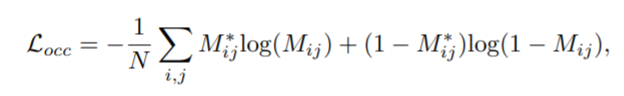
위에서 구한 정답 occlusion map과 예측 occlusion map을 binary cross entropy loss를 적용한 것이 Locc이다. 여기서 예측 occlusion은 정답 occlusion map과 구하는 방식은 동일하나, 정답 occlusion은 정답 disparity를 이용해서 left right cross consistency를 check 한다면 예측 occlusion map은 예측 disparity를 이용해서 left right cross consistency를 check 한다.

따라서 위의 occlusion loss와 기존의 정답 disparity와 예측 disparity를 빼는 loss인 Ldisp를 합쳐서 최종 loss가 된다.
이렇게 synthetic data에 대해서 stereo matching을 진행한다.
Supervised and Unsupervised Fine-tuning Stereo Matching Network on Realistic Data
그 다음은 realistic data에 대해서 fine tuning하는 과정이다.
두가지 방식이 있는데, supervised와 unsupervised 방식이 있다.
먼저 supervised 방식은 위에서 설명한 것과 동일하게 loss가 적용이 된다. 위에서는 synthetic data에 대해서 진행했다면, 여기서는 realistic data로 진행한다는 차이가 있다.
그 다음으로 unsupervised 방식은 여기서 새로 제안을 하였다. 먼저 기존의 Godard 방식 arxiv.org/pdf/1609.03677.pdf
을 이용할 경우 blurry 한 문제가 있어서 이 방법을 그대로 사용하지 않고 새로운 방식으로 진행을 하였다.

먼저 기존의 Godard 방식에서 occlusion을 고려한 loss를 적용한다. occlusion을 고려하면 부정확하게 나오는 부분을 피할 수 있다.

그 다음으로는absolute regularization loss로 여기서 Dun은 finetuning을 시키지 않고 예측한 disparity이고, 그냥 D는 해당 네트워크에서 새로 예측한 disparity이다. 즉, 새로 예측해서 finetuning 되는 network에서의 결과와 finetuning 되기 전의 결과와 큰 차이가 없도록 regularization을 해주는 것이다. 여기서도 마찬가지로, occlusion을 고려 하였고, gama3은 regularization 상수이다.

그 다음 relative regularization loss로 예측 disparity의 gradient smoothness를 측정한다.
따라서 최종 loss는 아래와 같다.


위의 그림을 보면 해당 loss를 사용한 것이 훨씬 잘 나오는 것을 확인할 수 있다.
Train Monocular Depth Network by Distilling Stereo Network

그 다음 마지막으로, monocular depth estimation인데, 여기서는 정말 간단하다.
여기서 D~은 monocular network로 부터 예측된 disparity map이고, D는 위에서 finetuning까지 완료된 stereo network를 통해서 나온 disparity map이다. 이 두개를 L1 loss를 적용한다. 이것이 전부이다.

위의 그림은 stereo network에 finetuning을 하지 않고 적용했을 때와 stereo network에 unsupervised 방식으로 finetuning을 한 후 적용했을 때, stereo network에 100개의 real data를 가지고 supervised 방식으로 finetuning 후 적용했을 때의 결과 이미지를 나타낸다.

위의 테이블은 Quantitative 결과를 나타낸 것이다.
결과가 많이 향상 된 것을 확인 할 수 있다.
이상으로 해당 논문 리뷰를 마치도록 하겠습니다.
질문이 있거나 혹시 잘못된 내용이 있다면 언제든 댓글로 달아주세요.



