안녕하세요 정말 오랜만이죠...
오늘 제가 리뷰할 논문은 이번 ECCV에 발표된 논문입니다.
제목은 MTI-Net: Multi-Scale Task Interaction Networks for Multi-Task Learning 입니다.
먼저 해당 논문의 주된 contribution을 설명하자면
1. Multi scale Multi modal distillation unit을 통해 모든 scale에서 task 상호 작용을 명시적으로 모델링한다.
2. Lower scale이 higher scale에게 선별된 task 정보를 전파하는 feature propagation module을 사용한다.
3. 모든 scale의 feature들, 정제된 task feature들을 모아서 최종 결과를 출력한다.
입니다.
제가 이해한 바로 이제 설명을 시작하도록 하겠습니다.
1. Multi-task learning by multi-modal distillation
Backbone과 task specific head는 network의 front-end이다. Task specific heads는 backbone network에서 shared된 feature보다 더 task-aware한 각 task feature을 생산한다.
[즉, 다시 말하자면,,, backbone에서는 공통된 shared feature를 추출가능, task specific heads에서는 그 해당하는 task에 맞는 feature를 추출 가능]
그리고 task specific feature 정보는 final task 예측치를 만들기 전에 multi-modal distillation unit을 통해 결합된다.
몇몇 task들은 front-end network를 통해서 예측되고, 몇몇 task들 (보조적인 task라고 알려진) 그들은 final task의 성능을 향상 시키기 위해서 쓰이게 된다.
[예를 들어 아래 그림과 같이 front end를 통해서 여러 task에 대해서 initial prediciton 결과가 나온다 - 그림 위에서부터 순서대로 depth prediction, normal prediction, segmentation prediction, edge prediction 그리고 나서 multi modal distillation module을 통해서 보조적인 task들은 다른 task의 성능 향상을 위해 이용된다. ex) depth의 더 정확한 final prediction을 위해서 multi modal distillation module에서 normal 을 이용, segmentation의 final prediction을 위해서 multi modal distillation module에서 edge를 이용 ]

Notation을 정리하자면,
Backbone features : shared features of the backbone network
Task features : The task-specific feature representation of each task-specific head
Distilled task features : The task features after multi-modal distillation
Initial task predictions : The per-task predictions at the front-end of the network
Final task predictions : The network outputs
여기서 Backbone feauters와 task features 그리고 distilled task features는 single scale 또는 multiple scale로 정의 될 수 있다.
2. Task interactions at different scales
실제로 task들은 다양한 receptive field 크기에 대해 서로 다르게 영향을 미칠 수 있다.
*receptive field : 출력 layer의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기이다. 32x32x3 (RGB image) 인 경우 filter의 크기가 [5x5x3] 이라면 receptive field 는 5x5x3 이 된다. 필터의 크기와 같다.
Depth map의 local patch는 scene의 semantic에 대한 정보를 거의 제공하지 않는다. 그러나, receptive field를 확대하면 depth 맵이 사람의 형태를 보여주고 이는 scene의 semantic에 힌트를 줄 수있고, Local patch는 귀중한 정보를 제공 할 수 있다. (ex, task 간 가장자리의 local alignment를 개선하기 위해)

Task가 공통 local structure를 공유하는 정도를 정량화하기 위해 실험을 수행했다. 고정 크기의 kernel을 사용하여 각 task의 label 공간에있는 local patch의 픽셀 밀접관계를 측정했다.
해당 연구에서는 NYU dataset에 대해서 semantic segmentation, depth estimation, edge detection 3가지의 task를 고려하였다. semantic pixel들의 쌍은 두개가 같은 category에 속할 때 비슷한 것으로 여겨졌다. depth estimation task에 대해서는 픽셀 쌍 간의 상대적 차이를 임계 값으로 지정하고, 임계값 이하인 pixel들이 비슷하다고 하였다.
해당 논문에서는 픽셀 밀접도(친화도)를 모든 task에 대해 계산하여 task간에 유사하거나 다른 쌍이 얼마나 잘 일치하는지를 측정했다.
결과는 Fig.2b와 같은데
첫 번째로 친화성 패턴이 task 전반에 잘 일치하며 경우에 따라 쌍 대응의 최대 65 %까지 일치한다는 것을 알 수 있다. 이는 서로 다른 task가 이미지의 일부에서 공통 structure를 공유 할 수 있음을 나타낸다.
두 번째는 친화성 패턴이 task 전체에서 일치하는 정도는 receptive field에 따라 달라지며, 이는 사용된 dilation에 해당한다. 이것은 task 상호 작용의 통계가 항상 일정하게 유지되지 않고 scale, 즉 receptive field에 의존한다는 초기 가정을 검증한다.
이러한 발견을 바탕으로 다음 section에서 다양한 task의 정보를 여러 scale로 추출하는 모델을 소개한다. 그렇게함으로써 해당 논문은 1에 설명 된 모델(Fig 1의 모델)의 한계를 극복하면서 각 개별 scale에서 고유한 task 상호 작용을 잡아낸다.
3. Multi-scale multi-modal distillation
해당 논문은 여러 scale의 작업 상호 작용을 명시적으로 고려하는 multi task architecture를 제안한다.
해당 논문에서 제안하는 모델은 아래의 그림과 같다.

첫번째로, backbone network는 입력 이미지에서 multi scale feature 표현을 추출한다. Multi-scale feature 추출기는 semantic segmentation, object detection, pose estimation등에 사용된다.
1에서 설명한 것과 같이 먼저 multi-scale feature 표현을 통해서 각 scale 별로 initial task prediction을 만든다.
이 특정 scale에 대한 초기 task 예측 결과는 해당 scale에서 추출 된 backbone feature에 task 별 head를 적용하여 찾을 수 있다. 그 결과 task 별 장면이 다양한 scale로 표현된다. 이렇게하면 네트워크에 심층적인 supervision이 추가 될뿐만 아니라 task feature가 이제 각 scale에서 개별적으로 증류 될 수 있다. 이를 통해 2에서 제안한대로 특정 receptive field 크기에 대해 각각 모델링 된 여러 task 상호 작용을 가질 수 있다.
다음으로 spatial attention 메커니즘을 사용하여 다른 task에서 정보를 추출하여 task feature을 구체화한다.
그러나, 해당 모델의 multi-modal distillation 과정은 각각의 scale에서 반복된다. (multi scale, multi modal distillation)
이 증류된 scale s의 task의 k에 대한 task feature를 아래와 같이 표현한다.


위의 식 (1)에서

는 각각의 scale에서의 (scale이 s이고 task l인 Fil,s인 task feature에 적용된) spatial attention mask를 반환한다.
해당 논문의 접근 방식은 반드시 spatial attention의 사용으로 제한되지 않고, 모든 유형의 기능 증류(squeeze and excitation)과 같은 것에 쉽게 연결할 수 있다.
반복을 통해서 모든 scale에 대한 distilled task feature를 계산한다. 대부분의 filter 계산이 저해상도 feature 맵에서 수행되므로 해당 모델의 계산 오버 헤드가 제한된다.
4. Feature propagation across scale
각각의 scale에 대해서 초기 예측치를 만들고, multi-modal distillation을 통해서 task feature를 refine 한다.
그러나, 높은 해상도의 scale은 receptive field에 한계가 있기 때문에 초기 예측이 좋지 않을 수 있다. 그리고 그것은 low quality의 task feature를 이끌 수 있다. 이 것을 처리하기 위해서 해당 논문에서는 feature propagation mechanism을 사용하였다. 이것은 높은 해상도의 scale feature가 낮은 해상도의 scale과 task feature이 concate되고, 따라서 높은 해상도의 scale이 task feature를 task specific head에서 얻기 전에 낮은 해상도가 도와준다.
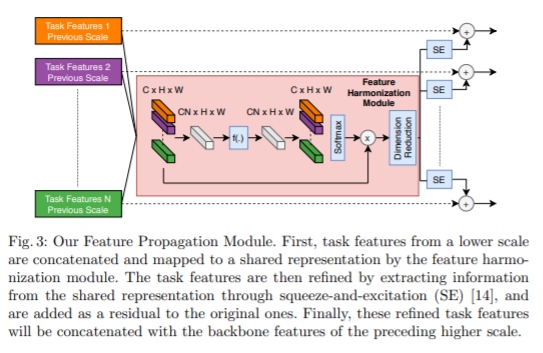
그리고, Feature Harmonization module은 받은 task feature을 shared representation으로 결합한다.
특히, N개의 task features set은 처음에 concate되고난 후 learnable non linear function f에 의해 처리 된다.
Output은 원래 채널 수 C와 일치하는 채널 차원을 따라 N chunck로 분할된다.그런 다음 task dimension에 따라 softmax 함수를 적용하여 attention mask를 생성한다. Attended feature은 concate되고 추가 처리되어 N · C에서 C로 채널 수를 줄인다. output은 모든 task의 정보를 기반으로 한 shared representation이다.
Refinement through Squeeze-And-Excitation.
Shared representation을 사용하면 task가 관련이 없을 때 성능이 저하 될 수 있다. 해당 논문에서는 Shared representation에 task 별 채널 gating 기능을 적용하여 이 상황을 해결한다. 이를 통해 각 task는 shared representation에서 관련 feature를 효과적으로 선택할 수 있다. Channel gating 메커니즘이 squeeze and excitation block으로 여기에 구현된다. SE 모듈을 적용한 후 개선 된 task feature이 원래 task feature에 residual로 추가된다.
5. Feature aggregation
3에서 설명 된 다중 스케일, 다중 모드 distillation은 모든 스케일에서 distilled 된 작업 기능을 생성한다. 후자는 가장 높은 스케일로 Upsampling되고 연결되어 모든 작업에 대한 최종 feature representation이 된다. 그만큼 최종 작업 예측은 작업 별 헤드별로 이러한 최종 feature representation을 다시 decoding하여 찾는다. 해당 논문의 모델은 PAD-Net과 유사하게 네트워크의 front end에 보조 작업을 추가 할 수 있다.
Result
아래는 NYUD dataset과 PASCAL 데이터에 대한 ablation study이다.


위의 식을 사용하여서 single task일 때와 multi task 일때의 차이를 측정하였다. m은 multi task b는 single task를 의미하며 위의 table을 보았을 때 해당 논문의 방식을 썼을 때 값이 NYU에 대해서는 최대 +10.91, PASCAL에 대해서는+3.36로 single 보다 더 성능이 향상 되어 나오는 것을 확인할 수 있다.

위의 Table3과 4는 scale이 다른 것을 몇개 사용했는지에 따른 성능 비교를 나타내고 있다.
Table 5는 PASCAL 데이터 셋에 대해서 sota와 비교한 성능 표 결과이다.

Table 결과를 보면 전체적으로 결과가 향상 된 것을 볼 수 있으며 , NYUD 에 대해서는 state-of-the art의 결과를 달성했다.
이상 논문 리뷰를 마칩니다!
저도 잘 모르는 부분이 많으니 혹시 질문이 있거나 하시면 댓글을 달아주시면 같이 공부하며 해결하도록 해보겠습니다.



