안녕하세요 오늘 제가 설명할 논문은 Joint learning으로 Saliency detection과 semantic segmentation을 수행하는 multi task 관련 논문입니다. 해당 논문은 ICCV2019에 accept이 되었습니다.
일단 논문에 대한 설명 이전에 Saliency Detection이 무엇인지 Semantic Segmentation이 무엇인지 해당 논문의 그림을 통해 간단히 설명 드리도록 하겠습니다.

먼저 Saliency Detection은 그림 1에서 보시는 것과 마찬가지로 관심있는 물체를 관심이 없는 배경으로 부터 분리시키는 것을 말합니다. 그림에서 관심있는 물체는 Bottle과 Person으로 Bottle과 Person을 제외한 나머지 부분은 검은색으로, Bottle과 Person은 흰색으로 이렇게 분리해주는 것이 Saliency Detection이라고 간단히 이해를 하면 될 것 같습니다.
그 다음으로는 Semantic Segmentation인데요, 말 그대로 의미론적으로 분리를 하는 것입니다.
위의 그림 1에서 Person과 Bottle과 Background가 있을 경우 Person인 영역은 분홍색으로, Bottle인 영역은 보라색으로, Background는 검은색으로 분리를 하듯이 Pixel 단위로 의미론적으로 같은 영역을 같은 색으로 표시를 해주는 것이 Semantic Segmentation이라고 생각하면 될 것 같습니다.
여기서 더해 해당 논문에서는 Weakly Supervised 방식으로 Semantic Segmentation을 수행합니다. Semantic Segmentation은 대부분 Supervised 방식으로 수행되고 있습니다. Supervised 방식이라하면, (a) input image를 주고, (c)와 같이 정답을 알려주고 그것을 학습하게 하는 방식입니다.
즉 이미지 각 pixel에 대해서 모든 정답을 제공해주는 것입니다.
하지만, Weakly Supervised 같은 경우는 모든 pixel에 대한 정보를 알려주는 것이 아니라 (a) input image를 주고, Bottle, Person이라는 Category만을 제공해준 후 (c)와 같이 예측하도록 하는 것입니다. 그래서 Supervised 방식보다 예측이 더 어렵습니다.
그럼 해당 논문에 대해서 설명 하도록 하겠습니다.

Network Architecture는 다음과 같습니다.
(a) input image가 들어가서 Segmentation network를 통과합니다. 그 후 Segmentation은 convolution layer와 upsample 과정을 거친 후 Segmentation을 수행
(b) input image가 들어가서 Segmentation network를 통과한 후 convolution을 거치고 Saliency aggregation module을 통과 한 후 각 class별 나온 결과를 concat 해주어 Saliency Detection을 수행합니다.
아래에서 조금 더 자세히 보도록 하겠습니다!
Saliency aggregation module 부터 보면

위의 수식에서 vi는 각 i번째 카테고리의 saliency score, Hi는 각 i번째 카테고리의 segmentation 결과입니다.
즉 위의 Network architecture 그림에서 각 class 별 나와있는 v1 ... v20까지가 위의 수식에서의 vi이며 이는 Saliency score이고, Hi는 그림에서 v1...v20바로 위에 있는 것으로 Segmentation 관련 결과이며 spatial 정보를 담고 있습니다.
Saliency aggregation module에서는 즉 vi와 Hi를 각 class별 element wise 곱을 해준 후 더합니다.
이제부터 주요 Loss들을 설명하도록 하겠습니다.
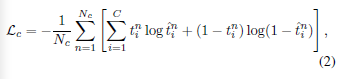
먼저 Lc Loss인데요, 여기서 tin은 n번째 이미지 안에 i번째 카테고리가 존재하느냐 안하느냐를 말합니다. 존재하면 tin = 1, 존재하지 않으면 tin = 0입니다.
예를 들어서 설명을 드리도록 할게요. Person의 category가 10번, Bottle의 category가 5번이라고 했을 때
그리고 확인할 전체 이미지가 30장 있을 때, 1번 사진부터 30장의 사진까지 (식에서는 n = 1부터 Nc까지) 모든 사진을 확인하는 것입니다. 만약 2번 image 안에 Person이 있으면, t210 = 1 인 것 입니다. 그렇게 2번 image 안에 내가 확인할 category 수만큼 모두 확인을 해주는 것입니다.
그리고 t^in은 image의 segmentation map을 통해 각 pixel에 어떤 category가 존재하는지 예측한 probability입니다.
즉 여기서 tin은 정답이라고 보면 되고, t^in은 예측한 것이라고 보면 될 것 같습니다.
그래서 각 category별 모든 image에 대해서 내가 예측한 값과 실제로 그 category가 있는지에 대해서 Loss를 주는 것입니다.

그 다음으로는 Ls1 Loss 입니다.
위의 Loss와 굉장히 비슷하죠. 위에서는 sementic segmentation에 관련해 loss를 재주었다면 이번에는 saliency detection 관련된 loss 입니다. 여기서 smn은 예측한 saliency 결과이고, ymn은 정답 saliency 입니다.
해당 논문에서 Saliency detection에서는 Supervised 방식으로 진행한 것을 알 수 있습니다.
위의 Lc는 image-level category labels 이고, Ls1은 pixel-level saliency labels 입니다.

그 다음으로 마지막 Ls2 Loss 입니다.
여기서 i는 category를 의미하며, m은 category i에 속한 pixel이고, n은 image의 개수를 의미합니다.
즉 모든 image에 대해서 각 category에 맞는 pixel인지 확인하기 위한 것입니다.
간단히 설명하자면, Lc는 image-level로 해당 이미지에 Person, Bottle 이 있는지 없는지를 알아내는데 사용이 되는 것이고, Ls1은 Saliency detection으로 Saliency와 관련된 정답을 주고 pixel-level로 saliency를 예측하는데 사용되는 것이며,
마지막 Ls2는 Lc에서 image-level로 파악한 것을 이제는 pixel-level로 각 pixel이 해당 class(category)에 속하는지를 위해 사용되는 Loss 입니다.
결과는 다음과 같습니다.

위의 사진은 Saliency Detection 결과입니다. 굉장히 잘 나오는 것을 확인할 수 있습니다.

Weakly Supervised Semantic Segmentation 결과입니다.
해당 논문은 Joint Learning으로 Saliency Detection과 Semantic Segmentation 두가지 task를 수행한다는 점과 Semantic Segmentation을 Weakly로 수행을 하였다는 점, 그리고 Saliency Detection과 Semantic Segmentation 둘다에서 성능이 괜찮게 나왔다는 점에서 제가 참고할 만하다고 생각 되어 리뷰를 해보았습니다.
해당 논문은 혼자 읽고 이해한 것으로 논문 리뷰에서 잘못된 점이 있을 수 있습니다. 잘못된 점이 있다면 언제든 댓글로 알려주시면 바로 수정에 반영하도록 하겠습니다.



